Voice is one of the most natural and efficient modalities in human-computer interaction (HCI) and has increasingly become the dominant input interface for mobile devices, wearable systems, and intelligent assistants. According to the latest forecasts, the global speech recognition market continues to show rapid growth in the coming years. However, speech interaction still faces numerous challenges in practical applications, particularly in noisy environments, privacy-sensitive situations, or for individuals with speech disorders. As a result, silent speech interfaces have emerged, aiming to accurately understand content without vocalization. This provides a promising solution for achieving natural and robust human-computer interaction through silent speech interfaces in scenarios where speech is unavailable or inconvenient.
However, existing silent speech interface solutions based on vision, wireless signals, or inertial sensors often face issues such as high invasiveness, environmental sensitivity, or complex deployment. This study proposes a novel ear-worn silent speech interaction system called Baro2Talk. As shown in Figure 1, the core insight of Baro2Talk's design is that even silent speech articulation can cause subtle pressure fluctuations in the ear canal. These pressure changes are primarily driven by articulatory movements involving the temporomandibular joint (TMJ), along with the jaw, tongue, and other oral structures, exhibiting consistent patterns that carry semantic information (as shown in Figure 2). This study refers to these sequences as TMJ-dominated Pressure Variation Sequences (TPVS). This provides an opportunity to establish a mapping model between intra-ear pressure changes, their underlying cause (TMJ movement), and the resulting semantics.
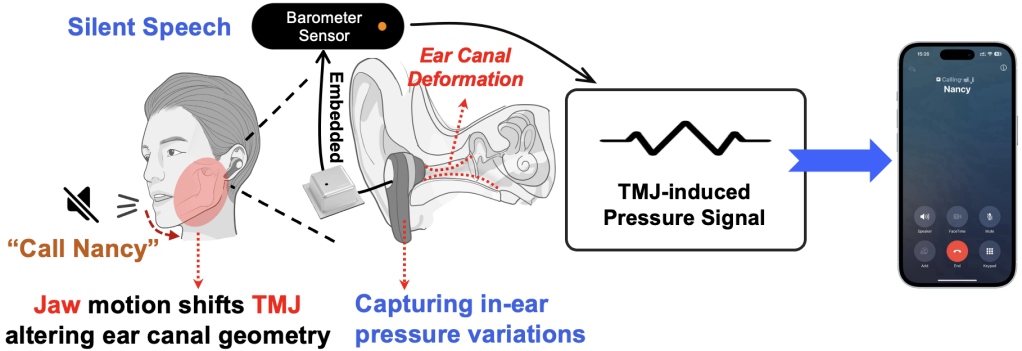
Figure 1 Schematic diagram of the Baro2Talk concept
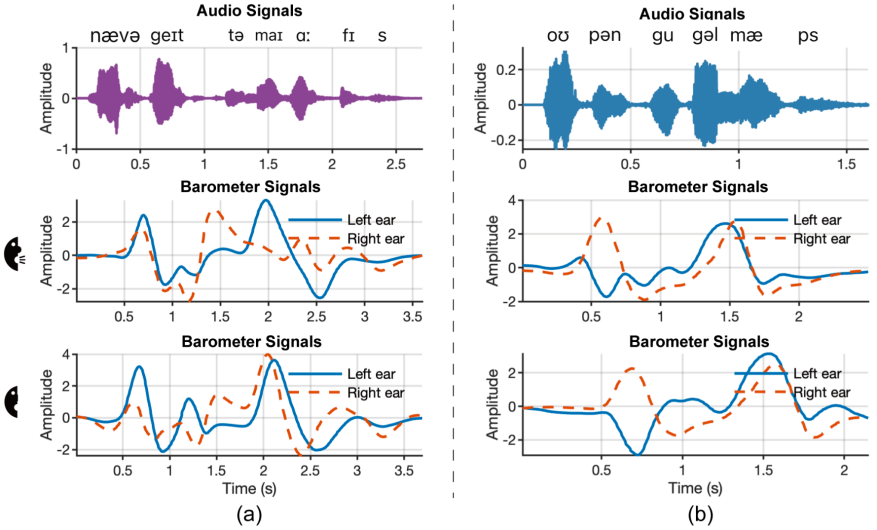
Figure 2 Examples of TPVS from two phrases
To this end, this study embeds a miniature barometer into standard earbuds to capture TPVS and utilizes it to reconstruct Mel-spectrograms rather than directly restoring text content. This approach is adopted because the sampling rate of the pressure signal (approximately 100 Hz) is significantly lower than that of audio signals, resulting in a substantial dimensional mismatch between the low-frequency TPVS and high-dimensional text embeddings. Directly mapping TPVS to text would require massive amounts of data. In contrast, Mel-spectrograms transform TPVS into a high-frequency representation conforming to speech characteristics, bridging the modal gap while preserving key features such as formants and pitch contours. Furthermore, since Mel-spectrograms serve as the standard input for general-purpose automatic speech recognition systems (e.g., Whisper), they become an ideal intermediate representation.
However, this study still faces three key challenges:
Low signal-to-noise ratio and susceptibility to interference in pressure signals. This study proposes a data preprocessing pipeline, including DC drift removal, band-pass filtering, and signal amplification, to reduce noise and clarify deformation signals. An enhanced short-term energy detection method with local stability checks is employed to extract silent speech deformation events from continuous TPVS.
Inter-user variability and diversity in speaking rhythms. As shown in Figure 3, this study trains a Baro-Encoder using domain adversarial learning to extract user-invariant semantic features. Additionally, a rhythm-aware data augmentation strategy is designed to generate time-warped variants of TPVS, enhancing robustness to variations in speaking rate.
Non-acoustic modality and lack of fine-grained supervision. As illustrated in Figure 4, unlike speech signals based on vocal cord or speaker vibrations, TPVS originates from internal human articulatory movements and contains no acoustic energy. Its spectrogram is not inherently meaningful in the speech domain, making direct mapping to audio spectrograms infeasible. Moreover, silent speech lacks aligned phoneme or frame-level labels, hindering the use of traditional supervised regression or alignment-based models.
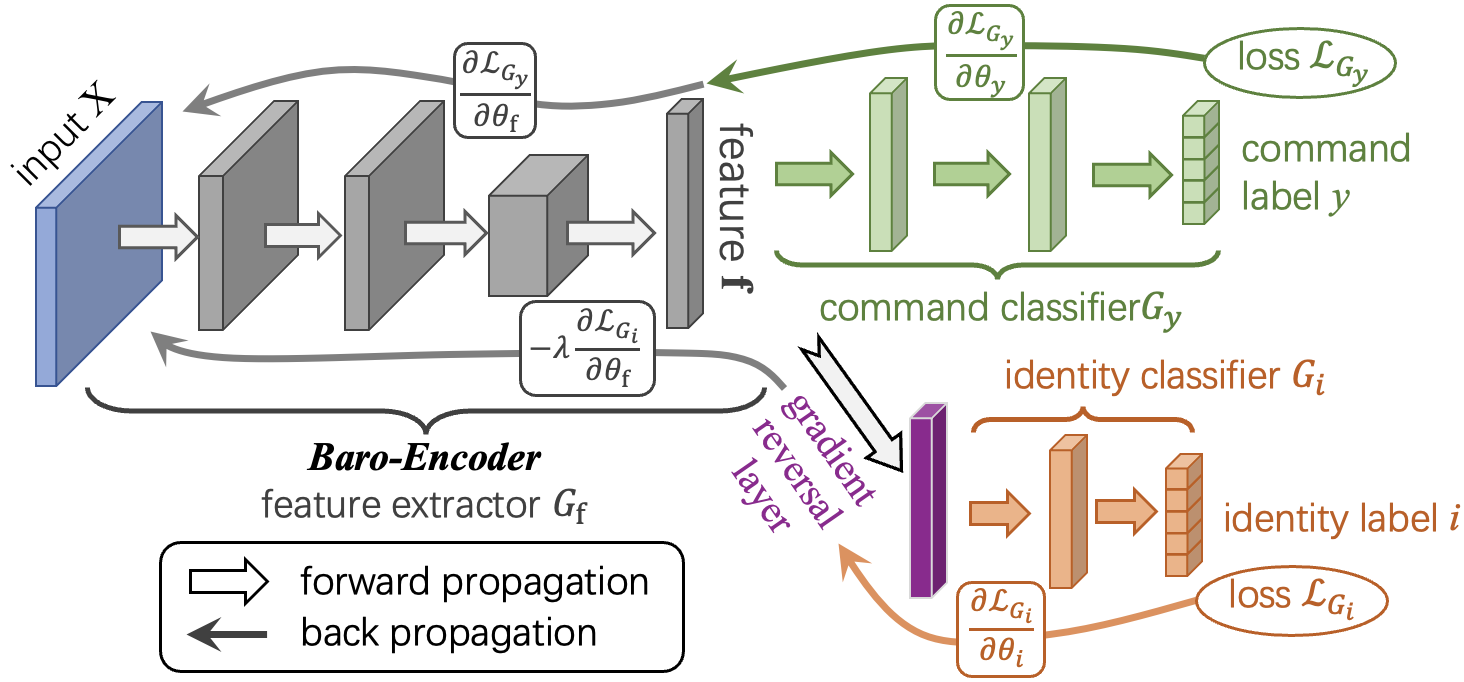
Figure 3 Illustration of the adversarial pre-training framework for Baro-Encoder
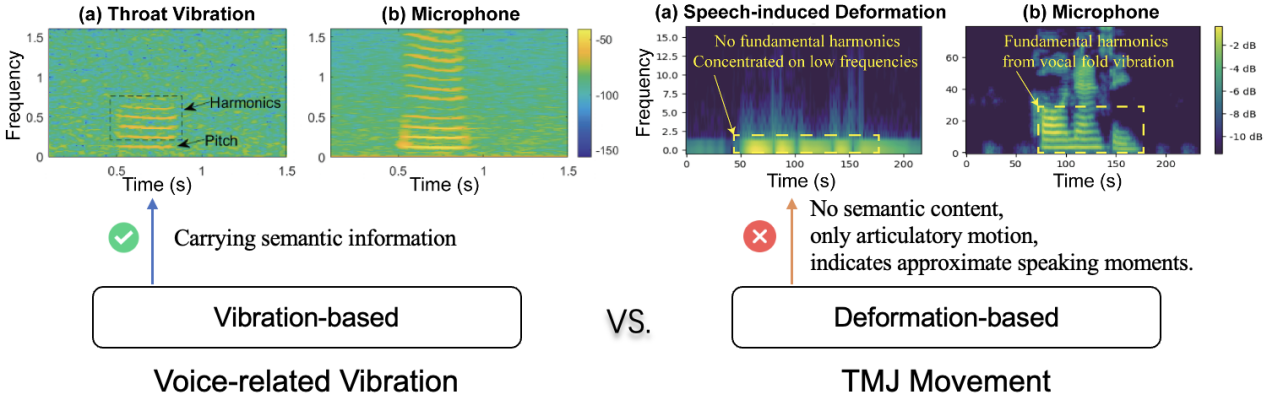
Figure 4 Comparison of Mel-spectrogram differences under various physiological mechanical movements
To address these challenges, as illustrated in Figure 5, this study proposes a three-stage Mel-spectrogram reconstruction pipeline that decouples semantic understanding from Mel-spectrogram generation. First, a semantic encoder named S-Former maps the complete TPVS of a sentence into a shared latent semantic space aligned with its text embeddings, circumventing the need for alignment. Second, the learned latent vectors are utilized to progressively generate coarse-grained Mel-spectrograms through a generative network, MS-GAN. Finally, it is refined through Phoneme Enhancement via Adaptive Residual Learning (PEARL), enabling high-fidelity reconstruction of Mel-spectrograms without acoustic supervision.
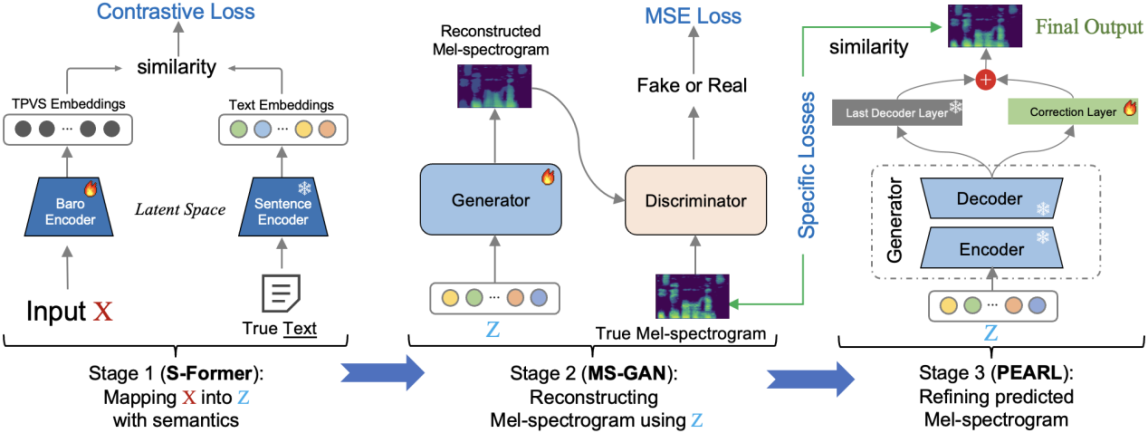
Figure 5 The three-stage Mel-spectrogram reconstruction pipeline
During silent speech interaction, the reconstruction quality of Mel-spectrograms directly determines the accuracy of subsequent ASR text predictions. Since TPVS contains no acoustic harmonics, the reconstruction process is highly challenging. As shown in Figure 6, this study employs ablation experiments to clearly demonstrate the contribution of each system module to the Mel-spectrogram reconstruction performance.
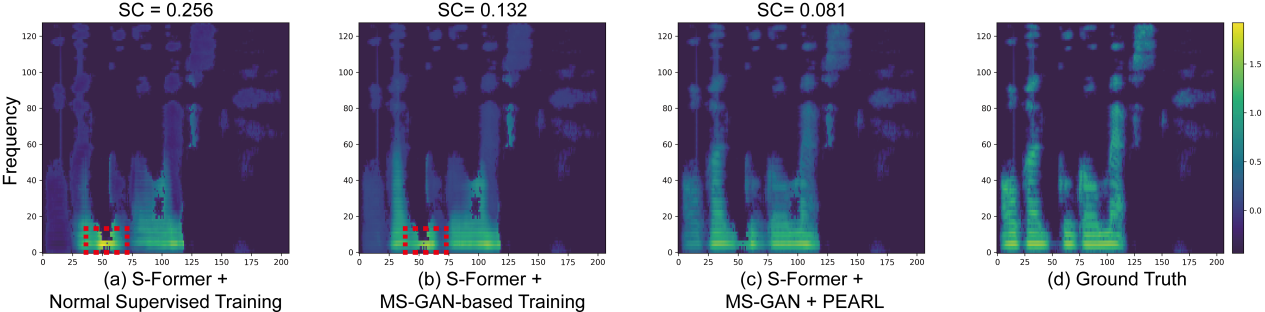
Figure 6 Comparison of Mel-spectrogram reconstruction performance
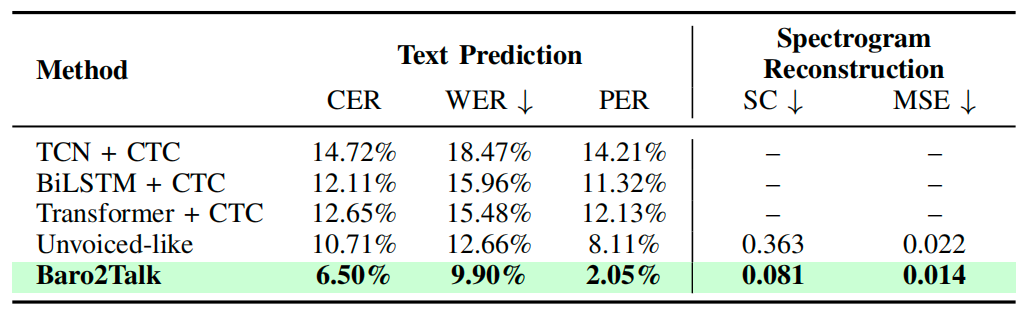
This study evaluated the system over a six-month period using datasets collected from 25 participants across silent and vocalized pronunciation conditions. As shown in Table 1, the system outperformed the representative SSI benchmark in both text prediction and Mel-spectrogram reconstruction.
Table 1 Text prediction accuracy and Mel-spectrogram reconstruction performance of different methods
This research work was presented at the IEEE International Conference on Computer Communications (INFOCOM 2026), a Class A conference recommended by the Chinese Computer Society.